Im Rahmen des Moduls „Open Data Hackathon“ im Wintersemester 2021/22 hat die Projektgruppe die Applikation „Baywatch“ entwickelt. Das Ziel der Anwendung war es, ein Modell so zu trainieren, dass es eine Prognose geben kann, wie stark die Auslastung von Parkplätzen an einem zukünftigen Tag sein wird. Der Fokus der Anwendung lag dabei auf den Parkplätzen in der Nähe des Strandes in Scharbeutz.
An einem warmen Tag mit dem Auto zum Strand zu fahren, kann zu einer langen Fahrt mit Stau und zu einer langen Parkplatzsuche führen. Um diese Probleme zu vermeiden und besser vorausplanen zu können, wird ein Modell anhand von Daten aus dem vergangenen Jahr darauf trainiert, Rückschlüsse für das zukünftige Jahr zu ziehen. Dafür kombiniert die Web-Anwendung „Baywatch“ verschiedene Faktoren miteinander, weshalb Menschen zum Strand gehen. Dies beinhaltet Datensätze, wie die Anzahl der belegten Parkplätze in Scharbeutz zu verschiedenen Uhrzeiten und Tagen, Temperatur- und Niederschlagsdaten sowie den Ferienzeitraum in Schleswig-Holstein. Die Datensätze stammen von Open Data Schleswig Holstein [1] und IPS-Modelle [2].

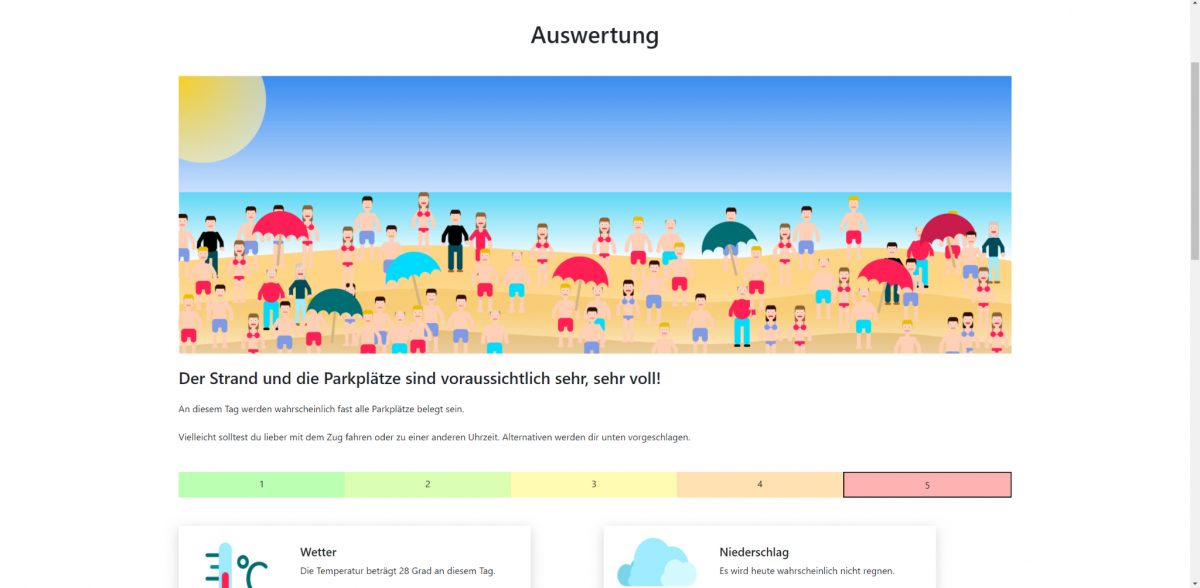
Der Aufbau der Applikation sieht vor, dass zunächst ein Tag und eine Uhrzeit ausgewählt wird. Daraufhin läuft im Hintergrund mithilfe der trainierten Modelle die Berechnung für die Vorhersage. Abschließend können die Nutzer:innen sich das Ergebnis ansehen. Das Ergebnis besteht aus einem Text, einer Skala und einer Aufschlüsselung der verschiedenen Faktoren, die die Prognose bedingt haben. Die Auswertung bestimmt eine von fünf verschiedenen Stufen von sehr geringer Auslastung (1) bis zu extrem hoher Auslastung (5). Zusätzlich wird die Auslastung auf den verschiedenen Parkplätzen angezeigt und die Auslastung zu jeder Stunde. Auch wenn der Strand zu der gewünschten Zeit wahrscheinlich voll sein wird, werden auf diese Weise Alternativen vorgeschlagen, auf welchem Parkplatz oder zu welcher Uhrzeit sie die besten Chancen auf einen freien Parkplatz haben.
Umsetzung Frontend und Backend
Für die Umsetzung der Webseite wurde Flask [3] benutzt, ein Webframework welches in Python geschrieben wurde und diese Programmiersprache auch selbst verwendet. Es wurde aufgrund der guten Erweiterbarkeit das Framework ausgesucht, da sich besonders die trainierten Modelle sowie weitere notwendige APIs gut integrieren lassen. Flask an sich ist relativ einfach gehalten. Es besitzt einen eigenen Webserver, welcher zum Testen und Aufsetzen der Webseite verwendet werden kann und somit einen großen Vorteil bietet.
Die Webseite an sich wurde mit normalem HTML-Code und CSS gestaltet. Flask erlaubt es, HTML-Dateien einfach einzubinden. So kann jede beliebige Seite verwendet werden, mit den passenden dazugehörigen CSS und Javascript-Dateien.
Für das Aussehen der Webseite wurde Bootstrap eingebunden und für ein einheitliches Design verwendet. Die entsprechende Logik der Seite wurde mit Javascript umgesetzt. Nachdem die Daten auf der ersten Seite eingegeben wurden, werden diese durch Python-Code ausgelesen und an die Wetter-API übergeben, welche im Anschluss das Wetter zurückgibt. Nach dem gleichen Prinzip werden eventuelle Ferienzeiten und Feiertage bestimmt. Mit diesen Daten wird im Anschluss die Stufe durch das trainierte Modell berechnet und an die Webseite übermittelt, wo die entsprechende Auswertung angezeigt wird.

Aufbereitung der Parkplatz Datensätze
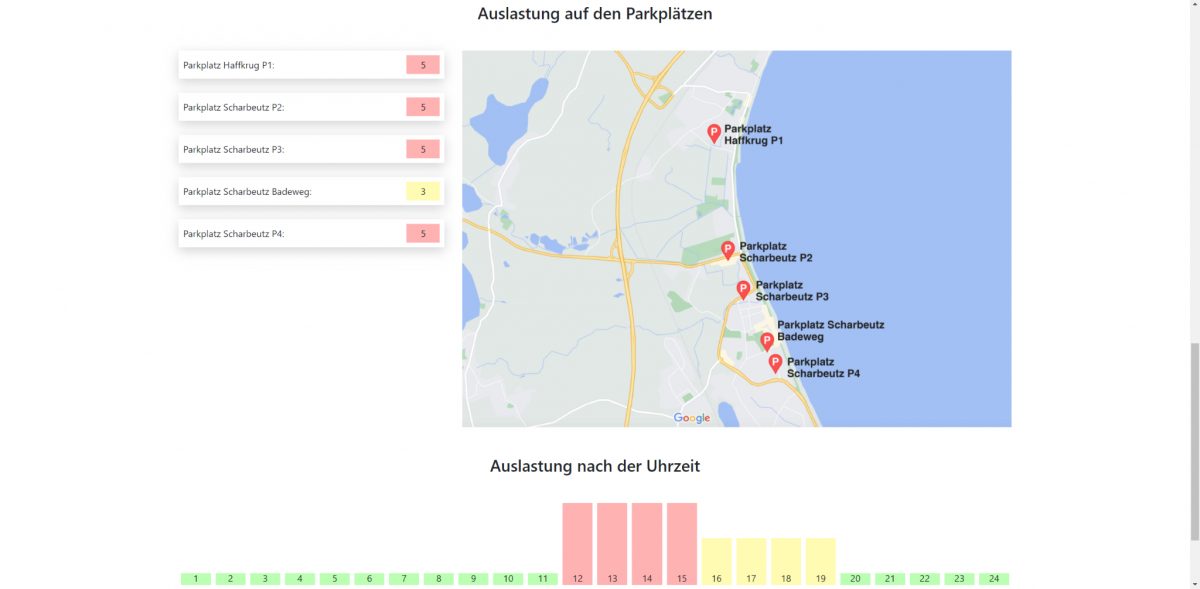
Um eine Vorhersage treffen zu können, wurden mehrere öffentliche Datensätze herausgesucht, mit deren Hilfe ein Modell trainiert werden konnte. Zunächst wurden dafür Datensätze heruntergeladen, welche die Parkplatzauslastung von einzelnen Parkplätzen in Scharbeutz angeben. In diesen wurde die Anzahl an geparkten Fahrzeugen angegeben. Die erste Schwierigkeit an den Datensätzen stellte eine nicht gleichmäßige Verteilung der Messintervalle dar. So wurde im Winter nur einmal die Stunde Daten erhoben und im Sommer alle 5 Minuten. Zusätzlich dazu waren die Messzeitpunkte in allen Dateien unterschiedlich. Deshalb bestand der erste Schritt darin, alle Datensätze in eine gleiche Struktur zu überführen. Die Bearbeitung der Datenstruktur erfolgte in Python. Die Datensätze wurden so aufbereitet, dass es zu jeder vollen Stunde einen Datenpunkt gibt. So waren die Datenpunkte gleichmäßig über das Jahr verteilt, und die Datenstruktur war zeitlich in allen Datensätzen identisch. Da für die Vorhersage der Parkplatzauslastung fünf Stufen verwendet wurden, wurde die Auslastung der Parkplätze auch auf fünf Stufen runterskaliert.
Verknüpfung mit Einflussfaktoren
Um die Genauigkeit der Vorhersage zu stärken, wurden weitere Faktoren zu den einzelnen Datenpunkten ergänzt. Zunächst konnten Wetterdaten bestehend aus Niederschlag und Temperatur hinzugefügt werden. Hierbei kam es zu Schwierigkeiten, da in den Datensätzen teilweise Einträge gefehlt haben. Zusätzlich wurden auch die Ferienzeiten mit berücksichtigt. In den folgenden Bildern lässt sich gut erkennen, welchen Einfluss die einzelnen Attribute auf die Anzahl der geparkten Fahrzeuge haben.
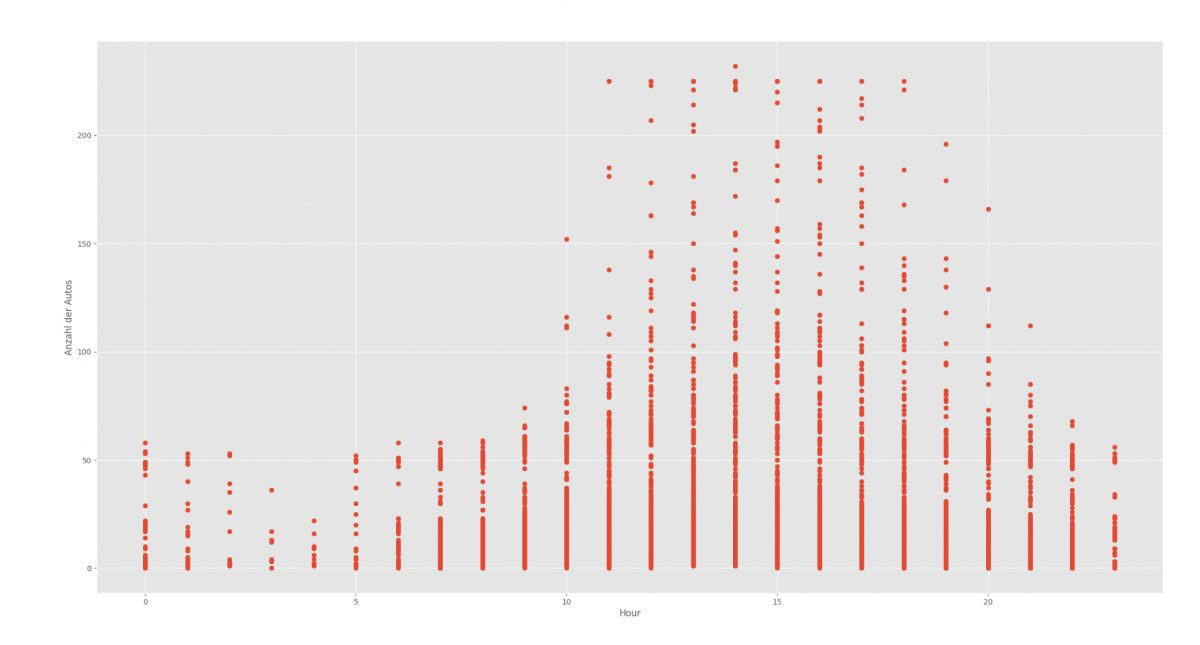
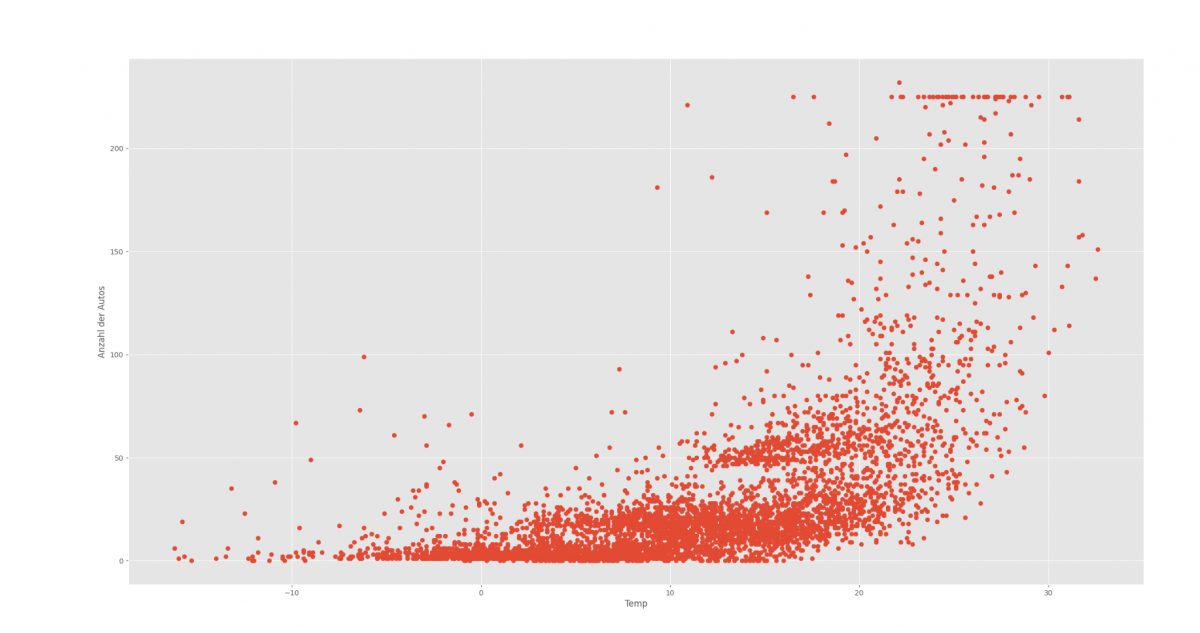
Visualisierung von beispielhaften Einflussfaktoren Trainieren der Machine Learning Modelle
Das Trainieren der Modelle wurde mit sklearn [4] in Python vorgenommen. Zu Beginn wurden unterschiedliche Algorithmen ausgetestet. Anschließend wurde verglichen, durch welches die höchste Genauigkeit erzielt werden kann. Bei Fehlern wurde hierbei auch darauf Rücksicht genommen, wie stark die Abweichungen von der richtigen Lösung sind. Schlussendlich wurde der Algorithmus “K nearest Neighbours” ausgewählt. Für die Anwendung wurden Modelle mit den Daten aller Parkplätze trainiert. Zusätzlich gibt es pro Parkplatz noch ein eigenes Modell, um die unterschiedliche Auslastung der Parkplätze zu bestimmen. Das Modell, welches die allgemeine Vorhersage trifft, hat eine Genauigkeit von 93,3% aufgewiesen. Die trainierten Modelle konnten abschließend gespeichert und in der finalen Webseite aufgerufen werden.
Fazit und Ausblick
Hinsichtlich der Datenverarbeitung und des Trainierens der Modelle war auffällig, dass ein Großteil der Arbeitszeit mit der Aufbereitung der Datensätze verbracht werden musste. Datensätze liegen meist nicht in einer geeigneten Formatierung vor und weisen häufig Fehler auf, welche man mühselig entfernen muss. Bei der Gestaltung und dem Aufsetzen der Webseite kam es zu keinen Schwierigkeiten. Auch der erstmalige Einsatz des verwendeten Frameworks verlief ohne Probleme und konnte alle unsere Ansprüche gut umsetzen.
Die entwickelte Webseite könnte in Zukunft noch erweitert werden. Hierzu könnten weitere Aspekte, welche für die Auslastung der Parkplätze eine Rolle spielen mit in die Modelle einbezogen werden. Auch wenn schon eine hohe Genauigkeit erreicht wurde, kann man diese noch weiter verbessern und genauer werden lassen.
Weiterhin werden bisher nur die Parkplätze in Scharbeutz berücksichtigt, was in Zukunft noch erweitert werden könnte. Im Rahmen des Hackathons wurde ein solides Grundgerüst erschaffen, welches noch Möglichkeiten bietet, erweitert zu werden.
Projekt von: Anita Hamurculu, Niklas Peper, Sarah Scheer, Daniel Schacht
[1] https://opendata.schleswig-holstein.de/dataset
[2] http://www.ips-modelle.de/cgi-bin/pub_wetterdownload.epl
[3] https://flask.palletsprojects.com/en/2.0.x/
[4] https://scikit-learn.org/stable/